
 官方微信
官方微信







 資訊頻道
資訊頻道近日,中國科學院自動化研究所深度強化學習團隊提出大模型驅(qū)動的機器人長序列決策與感知融合的RoboGPT方法,在具身智能測試平臺ALFRED榜單中取得第一名。
RoboGPT方法將大模型常識推理融入環(huán)境感知和探索中,有效避免了無效信息干擾,提升了復雜開放場景下環(huán)境感知的效率和泛化能力,解決了機器人環(huán)境適應性差、缺乏常識的難點。通過引入環(huán)境實時反饋,利用大模型強推理能力實現(xiàn)環(huán)境自適應的長序列任務分解,突破了機器人長序列復雜任務難以規(guī)劃,環(huán)境先決條件難以引入決策的難題。
該方法包含基于LLM的規(guī)劃器、重規(guī)劃(Re-Plan)和技能(RoboSkill)三個模塊。在給定任務指令后,基于LLM的RoboGPT規(guī)劃器可將其分解為多個子目標。RoboSkill 根據(jù)子目標執(zhí)行導航或操作技能,產(chǎn)生與環(huán)境交互的動作,并按順序完成所有子目標。如果某個子目標未完成,Re-Plan模塊會接收反饋信息,并根據(jù)從環(huán)境中接收到的數(shù)據(jù)生成新的規(guī)劃。
具體而言,團隊構建了一批高質(zhì)量的機器人規(guī)劃數(shù)據(jù),提出RoboGPT機器人規(guī)劃大模型,可完成上百種日常任務的規(guī)劃。機器人可根據(jù)智能體第一視角圖像獲得深度和分割信息,進行視覺SLAM(Simultaneous Localization and Mapping),得到語義地圖。在導航算法方面,團隊根據(jù)語義地圖設計了一種知識引導的小物體探索方法,使得機器人很快地找到目標物體。同時,相比于端到端的學習類方法,該方法易于遷移到其他機器人場景中,甚至是實體機器人場景,只需對根據(jù)第一視角圖像獲得深度和分割信息的模型進行場景適應。
RoboGPT方法在ALFRED的Valid Unseen數(shù)據(jù)和構造的通用任務Gen. Task的表現(xiàn)如表1所示。相較于目前基于ChatGPT(LLM-Planner)和基于模版的任務規(guī)劃方法(Prompter),RoboGPT方法在任務執(zhí)行成功率(SR, Success Rate)和任務規(guī)劃的正確性(HLP ACC, ACCuracy of High-Level instruction task Planning)上都取得了顯著的優(yōu)勢。相關工作在ALFRED的榜單中排名第一,并已整理成研究論文RoboGPT。
ALFRED是由華盛頓大學、CMU、Nvidia等聯(lián)合創(chuàng)建的具身智能公開測試平臺,目前已有60多個全球知名高校、科研院所和公司在該平臺上進行了公開測試。榜單提供了7類常見的日常指令任務,如“加熱蘋果放到櫥柜里”,要求機器人具有精準的環(huán)境感知能力和強推理能力,僅僅通過第一視角的圖像,完成復雜的指令任務。
榜單鏈接:
https://leaderboard.allenai.org/alfred/submissions/public
論文鏈接:
https://arxiv.org/abs/2311.15649
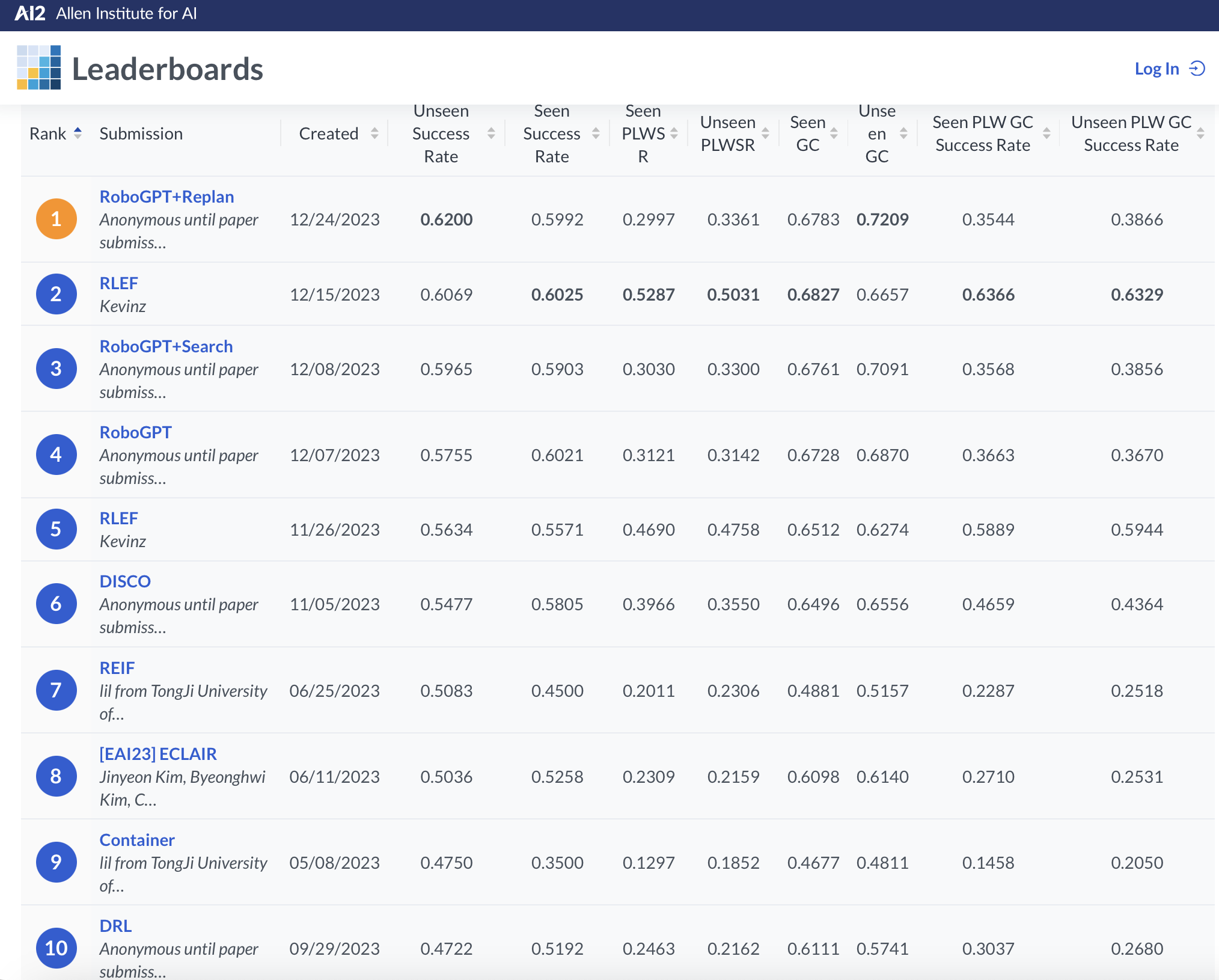
圖1. ALFRED榜單排名(截至2023年12月25日)
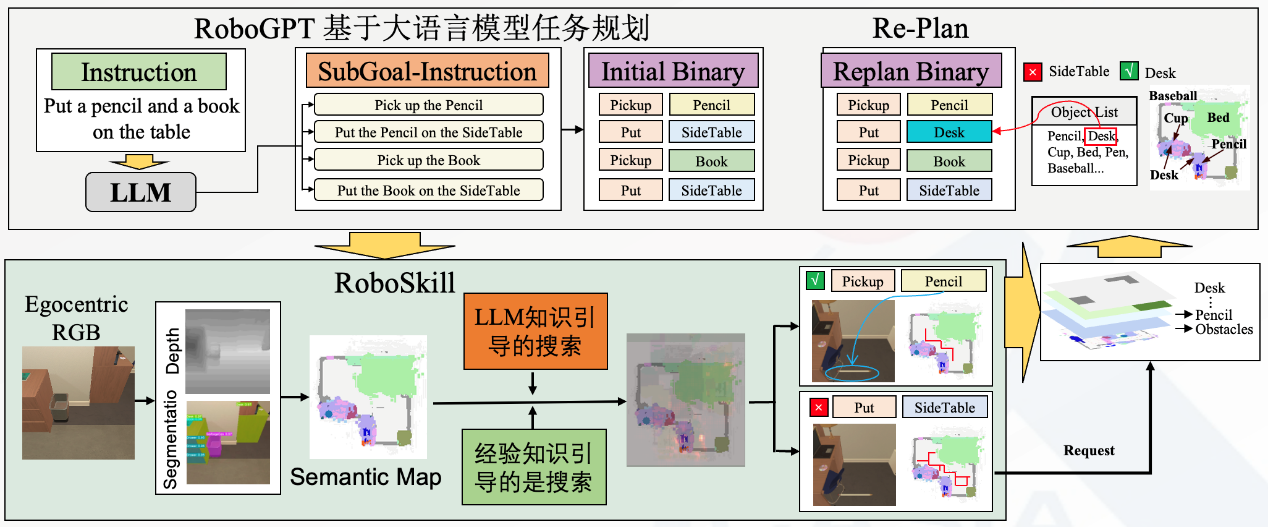
圖2. RoboGPT系統(tǒng)框圖
表1 ALFRED Valid Unseen和通用任務Gen.Task 實驗結果

來源:中國科學院自動化研究所

 北京市公安局海淀分局備案號:11010802023656號
北京市公安局海淀分局備案號:11010802023656號